

Linux培训
达内IT学院
400-996-5531
Linux培训
达内IT学院
400-996-5531
对于程序员来说,整个计算机系统由四个重要的模块组成,分别是:CPU,网络,磁盘,内存。在我们的程序或者系统出现问题时,我们应该分别有一定先后顺序的对这四块进行排查。而在Linux系统下,有很多高效的工具,可以帮助我们分析定位问题。本文对于Linux下常用的一些工具进行一些简单的介绍,帮助读者能对这些工具有一个初步的了解。如果有不对的地方,欢迎随时指正交流。
1.CPU
对于cpu我们主要介绍top,strace,perf,vmstat。
1.1 top
top命令可以实时动态地查看系统的整体运行情况,是一个综合了多方信息监测系统性能和运行信息的实用工具。
Top常用的可选参数和其对应的含义如下:
(1)-c:显示完整的命令;
(2)-d:屏幕刷新间隔时间;
(3)-i<时间>:设置间隔时间;
(4)-u<用户名>:指定用户名;
(5)-p<进程号>:指定进程;
(6)-n<次数>:循环显示的次数。
top执行起来的效果如下:
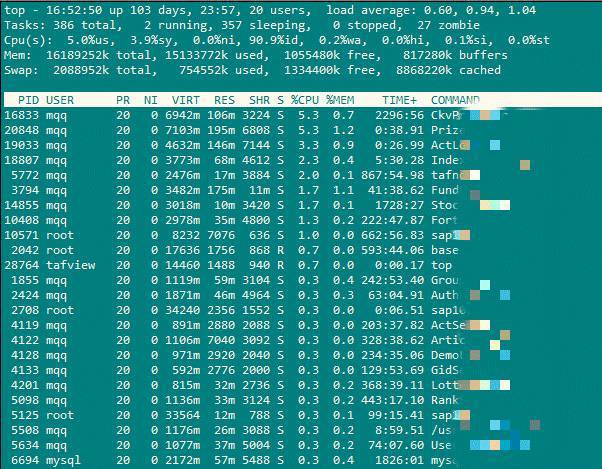
前五行是系统整体的统计信息。第一行是任务队列信息,第二行和第三行为进程和CPU的信息,最后两行为内存信息。下面对一些比较重要的参数进行说明。
Load average:0.60,0.94,1.04。load average表示系统在过去1分钟5分钟15分钟的任务队列的平均长度。这个值越大就表示系统CPU越繁忙。
Cpu(s):5.0%us(用户空间占用的cpu百分百),3.9%sy(系统空间占用的cpu百分比),0.0%ni(用户进程空间内改变过优先级的用户占用的cpu百分比),90.9%id(空闲cpu的百分比),0.2%wa(等待输入输出cpu的百分比)。
Mem:817280k buffers(用作内核缓存的内存量)。
Swap:磁盘交换区容量。
1.2 strace
strace可以跟踪到一个进程产生的系统调用,包含参数、返回值、执行消耗的时间。
strace的常用的选项以及选项对应的含义如下:
(1)-c 统计每一系统调用的所执行的时间,次数和出错的次数等
(2)-f 跟踪由fork调用所产生的子进程
(3)-t 在输出中的每一行前加上时间信息
(4)-tt 在输出中的每一行前加上时间信息(微妙级)
(5)-T 显示每一调用所耗的时间
(6)-e trace=set 只跟踪指定的系统调用。例如:-e trace=open,close,read,write表示只跟踪这四个系统调用。默认的为set=all
(7)-e trace=file 只跟踪有关文件操作的系统调用
(8)-e trace=process 只跟踪有关进程控制的系统调用
(9)-e trace=network 跟踪与网络有关的所有系统调用
(10)-e strace=signal 跟踪所有与系统信号有关的 系统调用
(11)-e trace=ipc 跟踪所有与进程通讯有关的系统调用
(12)-o filename 将strace的输出写入文件filename -p pid 跟踪指定的进程pid
例如执行 strace cat /dev/null,会得到如下输出:

每一行都是一条系统调用,等号左边是系统调用的函数名及其参数,右边是该调用的返回值。如果你知道你要找的是什么,你可以让strace只跟踪一些类型的系统调用。例如你需要看看在loadconfigure脚本里面执行的程序里面系统调用ececve的调用情况,则只需要输入这样一条shell命令:strace -f -o loadconfigure-strace.txt -e execve ./loadconfigure
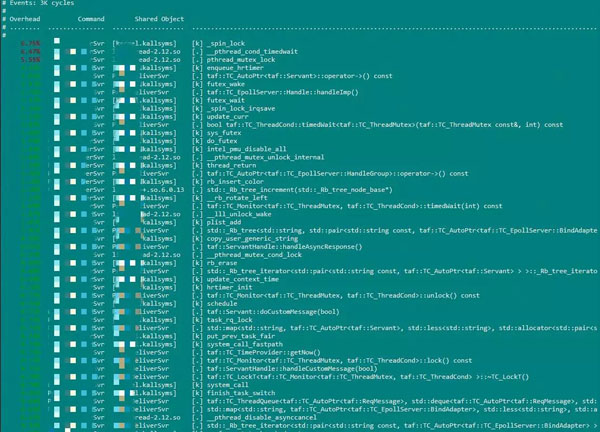
再例如,我们知道ActLogicSvr的进程号是16789,则可以执行strace -p 16789 -c来统计ActLogicSvr在某一段时间系统调用的统计情况。结果如下所示:
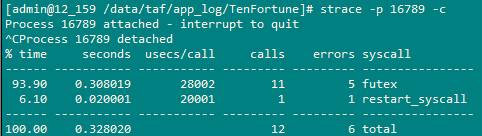
这里很清楚的告诉你调用了那些系统函数,调用次数多少,消耗了多少时间等等这些信息,这个对我们分析一个程序来说是非常有用的。
1.3 Perf
perf是Linux的性能调优工具。perf工具的常用命令包括top,record,report等。
perf top命令用来显示程序运行的整体状况。该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最耗时的内核函数或某个用户进程。Perf stat的运行效果如下:
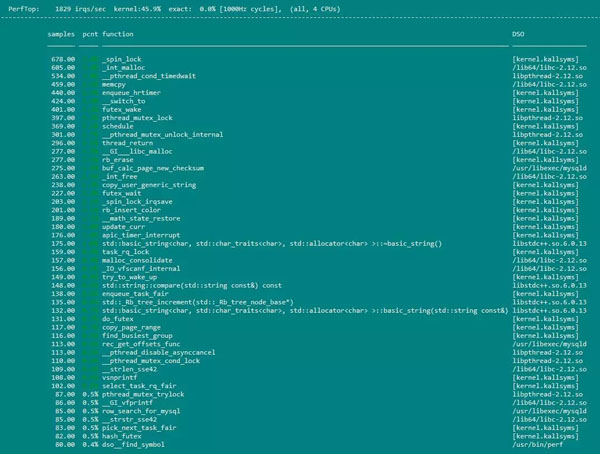
perf record命令则用来记录指定事件在程序运行过程中的信息,而Perf report命令则用来报告基于前面record命令记录的事件信息生成的程序运行状况报告。我们通常用命令perf record -g -p pid将进程在命令运行期间的各项指令运行所占CPU的比例存在perf.data里面(-g表示记录函数之间的调用关系)。再用perf report --call-graph --stdio将刚刚的统计结果展示出来。
perf record带-g选项时,perf report的运行效果:
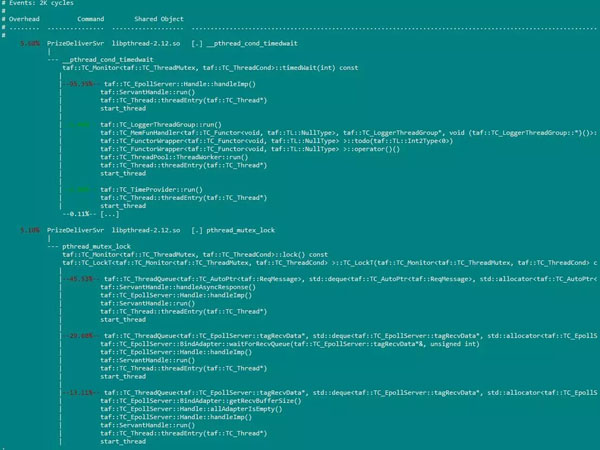
perf record不带-g选项时,perf report的运行效果:
1.4 vmstat
vmstat是一个很全面的性能分析工具,可以观察到系统的进程状态、内存使用、虚拟内存使用、磁盘的 IO、中断、上下问切换、CPU使用等。
vmstat的输出如下:

procs:
- r:运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)
- b:因为io处于阻塞状态的进程数。
memory:
-swap:使用虚拟内存大小
-free:空闲物理内存大小
-buff:用作缓冲的内存大小
-cache:用作缓存的内存大小
swap:
si:每秒从交换区写到内存的大小,由磁盘调入内存
so:每秒写入交换区的内存大小,由内存调入磁盘
io:
- bi:从块设备读入的数据总量(读磁盘)(KB/s)
- bo:写入到块设备的数据总量(写磁盘)(KB/s)
system:
- in:每秒产生的中断次数
- cs:每秒产生的上下文切换次数
cpu:
- us:用户进程消耗的CPU时间百分比
- sy:内核进程消耗的CPU时间百分比
- wa:IO等待消耗的CPU时间百分比
- id:CPU处在空闲状态时间百分比
2.网络
2.1 netstat命令
netstat命令用来打印Linux中网络系统的状态信息,可让你得知整个Linux系统的网络情况。
netstat的常用的选项如下:
(1)-a(all)显示所有选项
(2)-t(tcp)仅显示tcp相关选项
(3)-u(udp)仅显示udp相关选项
(4)-l(listen)仅列出有在Listen(监听)的服务状态
(5)-p(program)显示建立相关链接的程序名
(6)-r(route)显示路由信息,路由表
(7)-e(extend)显示扩展信息
(8)-c 每隔一个固定时间,执行该netstat命令。
在这里我们简单复习一下TCP三次握手和四次挥手的过程,便于下面解释netstat中tcp的各种状态。
TCP三次握手的过程如下:
(1)主动连接端发送一个SYN包给被动连接端;
(2)被动连接端收到SYN包后,发送一个带ACK的SYN包给主动连接端。
(3)主动连接端发送一个带ACK标志的包给被动连接端,握手动作完成。
TCP的四次挥手过程如下:
(1)主动关闭端发送一个FIN包给被动关闭端。
(2)被动关闭端收到FIN包后,发送一个ACK包给主动关闭端。
(3)被动关闭端发送了ACK包后,再发送一个FIN包给主动关闭端。
(4)主动关闭端收到FIN包后,发送一个ACK包。当被动关闭端收到ACK后,四次挥手动作完成,连接断开。
下面我们解释一下netstat中tcp连接对应的各种状态。
(1)LISTEN:侦听状态,等待远程机器的连接请求。
(2)SYN_SEND:在TCP三次握手期间,主动连接端发送了SYN包后,进入SYN_SEND状态,等待对方的ACK包。
(3)SYN_RECV:在TCP三次握手期间,主动接收端收到SYN包后,进入SYN_RECV状态。
(4)ESTABLISHED:完成TCP三次握手后,主动连接端进入ESTABLISHED状态。此时,TCP连接已经建立,可以进行通信。
(5)FIN_WAIT_1:在TCP四次挥手时,主动关闭端发送FIN包后,进入FIN_WAIT_1状态。
(6)FIN_WAIT_2:在TCP四次挥手时,主动关闭端收到ACK包后,进入FIN_WAIT_2状态。
(7)TIME_WAIT:在TCP四次挥手时,主动关闭端发送了ACK包之后,进入TIME_WAIT状态,等待最多2MSL时间,让被动关闭端收到ACK包。
(8)CLOSING:在TCP四次挥手期间,主动关闭端发送了FIN包后,没有收到对应的ACK包,却收到了对方的FIN包,此时进入CLOSING状态。
(9)CLOSE_WAIT:在TCP四次挥手期间,被动关闭端收到FIN包后,进入CLOSE_WAIT状态。
(10)LAST_ACK:在TCP四次挥手时,被动关闭端发送FIN包后,进入LAST_ACK状态,等待对方的ACK包。
netstat -te(显示出所有的tcp连接)执行起来的效果如下:
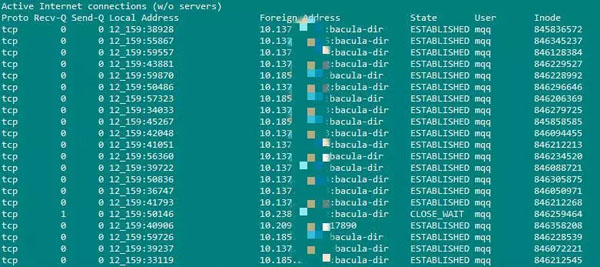
netstat的常用方法:
(1)netstat -p | grep 19626:得到进程号19626的进程所打开的所有端口
(2)netstat -tpl:查看当前tcp监听端口, 需要显示监听的程序名。
(3)netstat -c 2:隔两秒执行一次netstat,持续输出
2.2 lsof
lsof命令用于查看进程开打的文件,打开文件的进程,进程打开的端口(TCP、UDP)。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。在使用TCP的UDP的时候,系统在后台都为该应用程序分配了一个文件描述符。无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了通用接口。
lsof的使用示例如下:
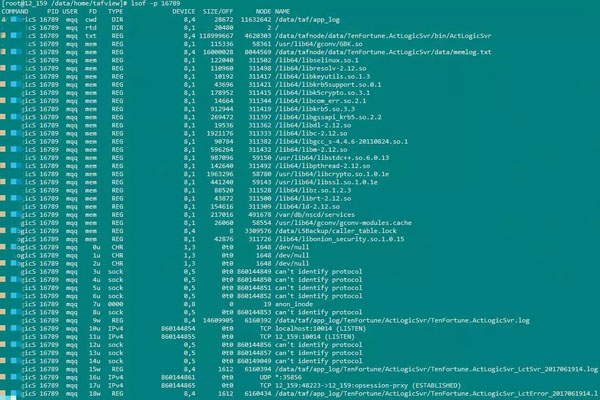
输出的各项的含义如下:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE:文件的大小
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
Lsof的常用方法:
(1)lsof abc.txt:查看所有打开了文件abc.txt的进程。
(2)lsof -p pid:显示进程打开的所有的文件。
2.3 tcpdump
tcpdump可以将网络中传送的数据包完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。
tcpdump的常用参数:
(1)-nn,直接以 IP 及 Port Number 显示,而非主机名与服务名称。
(2)-i,后面接要「监听」的网络接口,例如 eth0, lo, ppp0 等等的接口。
(3)-w,如果你要将监听所得的数据包数据储存下来,用这个参数就对了。后面接文件名。
(4)-c,监听的数据包数,如果没有这个参数, tcpdump 会持续不断的监听,直到用户输入 [ctrl]-c 为止。
(5)-A,数据包的内容以 ASCII 显示,通常用来捉取 WWW 的网页数据包资料。
(6)-e,使用资料连接层 (OSI 第二层) 的 MAC 数据包数据来显示。
(7)-q,仅列出较为简短的数据包信息,每一行的内容比较精简。
(8)-X,可以列出十六进制 (hex) 以及 ASCII 的数据包内容,对于监听数据包内容很有用。
(9)-r,从后面接的文件将数据包数据读出来。那个「文件」是已经存在的文件,并且这个「文件」是由 -w 所制作出来的。
tcpdump的常见用法:
(1)tcpdump -i eth1 host ***.***.***.***:抓取所有经过 eth1,目的或源地址是***.***.***.***的网络数据。
(2)tcpdump -i eth1 dst host ***.***.***.***:抓取所有经过 eth1,目的地址是***.***.***.***的网络数据。
(3)tcpdump -i eth1 src host ***.***.***.***:抓取所有经过 eth1,源地址是***.***.***.***的网络数据。
(4)tcpdump -i eth1 port 36000:抓取所有经过 eth1,目的端口或源端口是36000的网络数据。
(5)tcpdump -i eth1 src port 36000:抓取所有经过 eth1,源端口是36000的网络数据。
(6)tcpdump -i eth1 dst port 36000:抓取所有经过 eth1,目的端口是36000的网络数据。
(7)tcpdump -i eth1 'src host ***.***.***.*** && src port 36000':抓取所有经过 eth1,目的地址是10.136.12.1且目的端口是36000的网络数据。
(8)在10.136.12.1机器上我们通过top知道了ActLogicSvr的进程id为16789。然后通过netstat -ap | grep 16789得到ActLogicSvr监听的端口是10014。如下图所示:

然后我们通过 tcpdump -i eth1 'port 10014' -xxx抓取通过10014端口的所有的包。我们通过模拟接口测试的方法给ActLogicSvr发一条请求。抓到的包结果如下:
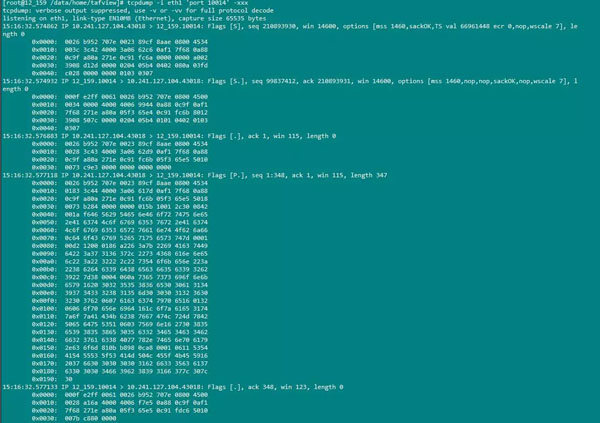

从抓到的包上我们可以清楚的看到tcp连接建立的三次握手到数据传输到tcp连接断开四次挥手的过程(前三个数据包是三次握手的过程,最后四个数据包是四次挥手的过程,中间的为数据传输所产生的网络数据包)。
3 内存
3.1 valgrind
valgrind 是在Linux程序中广泛使用的调试应用程序。它尤其擅长发现内存管理的问题,可以检查程序运行时的内存泄漏问题等。我们在使用valgrind时也主要用到它的内存泄漏检测功能,即memcheck功能。它检查所有对内存的读/写操作,并截取所有的malloc/new/free/delete调用。因此memcheck工具能够探测到以下问题:
(1)使用未初始化的内存
(2)读/写已经被释放的内存
(3)读/写内存越界
(4)读/写不恰当的内存栈空间
(5)内存泄漏
(6)使用malloc/new/new[]和free/delete/delete[]不匹配。
(7)src和dst的重叠valgrind的可选的参数以及对应的含义如下所示:
(1)-version 显示valgrind内核的版本,每个工具都有各自的版本。
(2)q –quiet 安静地运行,只打印错误信。
(3)v –verbose 更详细的信息, 增加错误数统计。
(4)-trace-children=no|yes 跟踪子线程
(5)-track-fds=no|yes 跟踪打开的文件描述
(6)-time-stamp=no|yes 增加时间戳到LOG信息
(7)-log-fd=<number> 输出LOG到描述符文
(8)-log-file=<file> 将输出的信息写入到filename.PID的文件里,PID是运行程序的进行ID
(9)-log-file-exactly=<file> 输出LOG信息到 file
(10)-log-file-qualifier=<VAR> 取得环境变量的值来做为输出信息的文件名。
(11)-log-socket=ipaddr:port 输出LOG到socket ,ipaddr:port
LOG信息输出:
(1)-xml=yes 将信息以xml格式输出,只有memcheck可用
(2)-num-callers=<number> show <number> callers in stack traces [12]
(3)-error-limit=no|yes 如果太多错误,则停止显示新错误? [yes]
(4)-error-exitcode=<number> 如果发现错误则返回错误代码 [0=disable]
(5)-db-attach=no|yes 当出现错误,valgrind会自动启动调试器gdb。[no]
(6)-db-command=<command> 启动调试器的命令行选项[gdb -nw %f %p]适用于Memcheck工具的相关选项:
(1)--leak-check=no|summary|full 要求对leak给出详细信息? [summary]
(2)--leak-resolution=low|med|high how much bt merging in leak check [low]
(3)--show-reachable=no|yes show reachable blocks in leak check? [no]
示例:valgrind --leak-check=full /usr/local/app/taf/tafnode/data/TenFortune.WeChatProxySvr/bin/WeChatProxySvr --config=/usr/local/app/taf/tafnode/data/TenFortune.WeChatProxySvr/conf/TenFortune.WeChatProxySvr.config.conf -trace-child=yes。执行的结果:
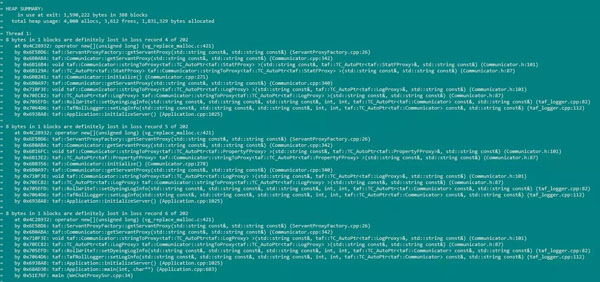
4 磁盘
4.1 iotop
iotop命令是一个用来监视磁盘I/O使用状况的top类工具。iotop具有与top相似的UI,其中包括PID、用户、I/O、进程等相关信息。Linux下的IO统计工具如iostat,nmon等大多数是只能统计到per设备的读写情况,如果你想知道每个进程是如何使用IO的就比较麻烦,使用iotop命令可以很方便的查看。
iostat命令选项:
-o:只显示有io操作的进程
-n NUM:显示NUM次,主要用于非交互式模式。
-d SEC:间隔SEC秒显示一次。
-p PID:监控的进程pid。
-u USER:监控的进程用户。
iotop的执行效果:

5 推荐阅读
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



